clustering
This article is provided by FOLDOC - Free Online Dictionary of Computing (foldoc.org)
clustering
Using two or more computer systems that work together. It generally refers to multiple servers that are linked together in order to handle variable workloads or to provide continued operation in the event one fails. Each computer is a multiprocessor system itself. For example, a cluster of four computers, each with 16 CPU cores, would enable 64 unique processing threads to take place simultaneously.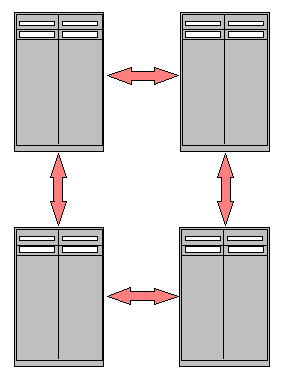 |
| Clustering |
|---|
| A cluster of servers provides fault tolerance and/or load balancing. If one server fails, one or more servers are still available. Load balancing distributes the workload over multiple systems. |
Copyright © 1981-2025 by The Computer Language Company Inc. All Rights reserved. THIS DEFINITION IS FOR PERSONAL USE ONLY. All other reproduction is strictly prohibited without permission from the publisher.